Maria Boritchev Computational Linguist
| About | Projects | DinG | Teaching | Publications | Resources |
|
MapAIE/CHAI Since 2023 |
Mapping and exploring ethics of AI |
| Tiphaine Viard, Mélanie Gornet, Simon Delarue, Maria Boritchev, Matthieu Labeau, Aina Garì Soler | |
|
We collect and analyze charters, documents and manifestos about "ethical AI", and use them as a defining corpus for AI ethics topics of interest. More information here: https://mapaie.telecom-paris.fr/. Relevant publications:
|
|
ANAGRAM Since 2024 |
AMR annotation of the DinG corpus |
| Jeongwoo Kang, Maria Boritchev, Maximin Coavoux | |
|
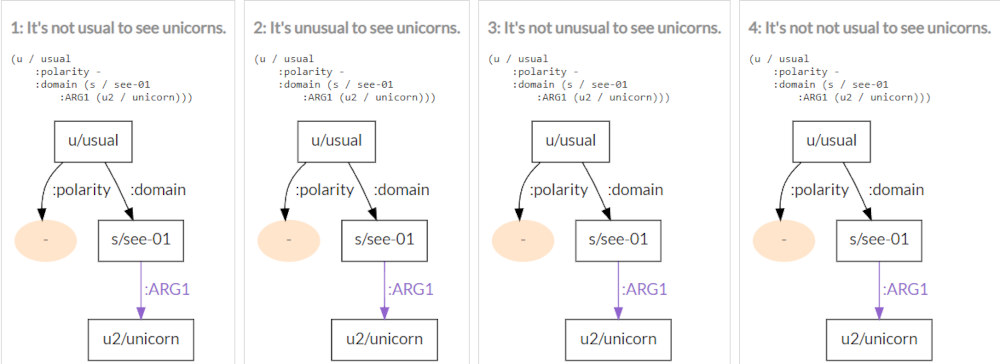
We are annotating a semantic corpus in French. We annotate the DinG corpus of transcriptions of spontaneous dialogues between players of Catan, in Abstract Meaning Representation (AMR), one of the most popular meaning representation frameworks. Since AMR does not cover some features of dialogue dynamics, we extend the framework to better represent spoken language as well as sentence structures specific to French. In addition, we provide an annotation guide detailing these extensions. Finally, we publish our corpus under a Creative Commons license (CC-SA-BY). Our work contributes to the development of semantic resources for French dialogue. We collected and transcribed 10 recordings of people playing the boardgame Catan, in French. We share the transcribed and anonymised data. We use this data as support for studying questions and answers in spontaneous French oral multilogues. Relevant publications:
|
|
DinG Since 2019 |
Dialogues in Games corpus |
| Maria Boritchev, Maxime Amblard | |
|
We collected and transcribed 10 recordings of people playing the boardgame Catan, in French. We share the transcribed and anonymised data. We use this data as support for studying questions and answers in spontaneous French oral multilogues. More information here and here: https://team.inria.fr/semagramme/projects/corpus-ding/ Relevant publications:
|
|
AMR w/ Orange Since 2023 |
Error analysis, questions, and AMR |
| Maria Boritchev, Johannes Heinecke, Frédéric Herlédan | |
|
We conduct an error analysis of AMR parsers' outputs in order to characterise these errors and come up with pre- and post- processing heuristics to patch these. We work on data in English, French, German, Spanish, Italian, and Polish. We analyse how adding few sentence-type specific annotations can steer the model to improve parsing in the case of questions in English. Relevant publications:
|